บทที่ 5 โครงสร้างข้อมูลแบบซ้อนใน#
โครงสร้างข้อมูลที่ใช้งานเป็นประจำในภาษาไพทอน คือ ลิสต์ และดิกชันนารี ภาษาไพทอนรองรับการเก็บข้อมูลอยู่สองประเภทใหญ่ ๆ ที่เราได้เรียนมาแล้ว
ข้อมูลแบบค่าเดี่ยว ได้แก่ เลขจำนวนเต็ม สตริง เลขทศนิยม และบูลีน
ข้อมูลแบบคอลเลกชัน ได้แก่ ลิสต์ ทูเปิล ดิกชันนารี เซ็ต
ข้อมูลแบบคอลเลกชันจัดเป็นโครงสร้างข้อมูลที่มีหน้าที่ในการเก็บข้อมูลเอาไว้หลาย ๆ ตัว ทำให้เกิดเป็นโครงสร้างขึ้นมา เช่น ลิสต์เป็นโครงสร้างมีลำดับ ดิกชันนารีเป็นโครงสร้างแบบมีการจับคู่ ในบทที่ผ่านมาเราได้เรียนรู้วิธีการใช้โครงสร้างข้อมูลเหล่านี้ในการเก็บข้อมูลแบบค่าเดี่ยวหลาย ๆ ตัวไว้ในโครงสร้างเดียวกัน เช่น ลิสต์ของตัวเลขเพื่อใช้เก็บรายการคะแนนของนักเรียนในห้อง ลิสต์ของสตริงเพื่อใช้เก็บรายชื่อของพนักงานในบริษัท ดิกชันนารีที่คีย์เป็นสตริงและแวลูเป็นตัวเลขเพื่อใช้เก็บคำและความถี่เกิดขึ้นของคำนั้น เซ็ตของสตริงเพื่อใช้เก็บรายการคำศัพท์ เป็นต้น

โครงสร้างข้อมูลทั้งสองประเภทนี้ไม่ตอบโจทย์การใช้งานบางประเภท ที่ต้องการโครงสร้างที่ซับซ้อนขึ้น โครงสร้างข้อมูลแบบซ้อนใน (nested data structure) คือ โครงสร้างข้อมูลที่เก็บโครงสร้างข้อมูลอีกประเภทนึงเอาไว้ โครงสร้างข้อมูลทั้งหมดที่เราได้เรียนมาแล้วสามารถเก็บโครงสร้างข้อมูลอื่น ๆ ซ้อนเข้าไปได้อีกชั้นหนึ่ง เพื่อรองรับข้อมูลที่มีโครงสร้างซับซ้อนขึ้น เช่น
ลิสต์ของลิสต์ของสตริง เพื่อใช้เก็บชื่อไฟล์และโฟลเดอร์ที่อยู่ในโฟลเดอร์อีกชั้นหนึ่ง
files = [
['file1.txt', 'file2.txt', 'file3.txt'],
['file4.txt', 'file5.txt', 'file6.txt'],
['file7.txt', 'file8.txt']
]
ลิสต์ของทูเปิลของสตริง เพื่อใช้เก็บรายชื่อที่มีทั้งชื่อจริงและชื่อเล่น
names = [
('เศรษฐา', 'นิด'),
('ประยุทธ์', 'ตู่'),
('ยิ่งลักษณ์', 'ปู'),
('อภิสิทธิ์', 'มาร์ค')
]
ลิสต์ของดิกชันนารี เพื่อใช้เก็บบทสนทนาในกลุ่มไลน์
tweets = [
{'user': 'nong-p1', 'message': 'พี่คะ โปรแกรมหนู error ค่ะ'},
{'user': 'nipun', 'message': 'ขอดูหน่อยครับ'},
{'user': 'nipun', 'message': 'ส่ง screenshot มาเลยครับ'},
{'user': 'p-p2', 'message': 'ปัญหาเดียวกันเลยครับ'}
]
ความท้าทายของการใช้โครงสร้างข้อมูลแบบซ้อนใน คือ การเข้าถึงข้อมูลในโครงสร้างข้อมูลที่ถูกซ้อนอยู่ ผู้ใช้จะต้องทราบว่าเมื่อเข้าถึงข้อมูลโดยใช้ [] แล้วค่าที่ได้คืนมาเป็นโครงสร้างข้อมูลประเภทใด และโครงสร้างข้อมูลนั้นเก็บข้อมูลประเภทใดอีก ในบทนี้จะมีคำถามให้ลองคิดตามดูว่าเมื่อรันโค้ดแล้วจะได้โครงสร้างข้อมูลประเภทใดคืนมา
ความท้าทายอีกประการหนึ่งของการใช้โครงสร้างข้อมูลแบบซ้อนใน คือ การเลือกใช้โครงสร้างข้อมูลที่เหมาะสมกับข้อมูลที่ต้องการจะเก็บ และไม่ซับซ้อนเกินไป หากเราเลือกโครงสร้างข้อมูลที่ซับซ้อนเกินไป จะทำให้อ่านโค้ดให้เข้าใจได้ยาก เมื่อผู้อื่นต้องนำโค้ดเราไปเขียนเพิ่มเติม ก็อาจทำให้ผิดพลาดได้ง่าย
ในบทนี้เราจะพูดถึงโครงสร้างข้อมูลแบบซ้อนใน ที่พบเห็นได้บ่อย ๆ ในการเขียนโค้ดเพื่อประมวลผลข้อมูล
ลิสต์ของลิสต์#
ในการใช้งานจริงเราใช้ลิสต์ของลิสต์เพื่อเก็บข้อมูลประเภทเดี่ยวทั้ง 3 ประเภท ลิสต์ของลิสต์ของตัวเลข (ลิสต์ที่มีลิสต์ย่อยที่เก็บตัวเลข) ลิสต์ของลิสต์ของสตริง และ ลิสต์ของลิสต์ของบูลีน
ลิสต์ของลิสต์ของตัวเลข#
ขอยกตัวอย่างการใช้ลิสต์ของลิสต์ของตัวเลข ซึ่งเป็นลิสต์ของคะแนนของนักเรียน โดยแต่ละคะแนนจะประกอบไปด้วย คะแนนเก็บ คะแนนสอบกลางภาค และคะแนนสอบปลายภาค โดยเราจะเก็บคะแนนของนักเรียนแต่ละคนไว้ในลิสต์ของลิสต์ของตัวเลข ดังนี้
scores = [
[10, 20, 30],
[40, 50, 60],
[70, 80, 90]
]
เราสามารถเข้าถึงคะแนนของนักเรียนคนที่ 2 ได้ดังนี้
scores[1]
ผลลัพธ์ที่ได้คือ
[40, 50, 60]
ซึ่งเป็นลิสต์ของคะแนนของนักเรียนคนที่ 2
ลิสต์ของลิสต์ของสตริง#
ในการประมวลผลภาษาธรรมชาติ ลิสต์ของลิสต์มักจะใช้เก็บประโยคหลาย ๆ ประโยค เราจะเก็บประโยค 1 ประโยคไว้ในลิสต์ของสตริงคำ เมื่อเราต้องเก็บหลาย ๆ ประโยคจึงกลายมาเป็นลิสต์ของลิสต์ของสตริงคำ
[['I', 'want', 'you'], ['I', 'need', 'you'], ['I', 'love', 'you']]
ถ้าหากเรามีข้อมูลเป็นลิสต์ของสตริงที่เป็นประโยคภาษาอังกฤษ เราสามารถเปลี่ยนให้เป็นลิสต์ของลิสต์ของคำได้ดังนี้
sentences = [
'I want you',
'I need you',
'I love you'
]
words = [sentence.split() for sentence in sentences]
ในคำสั่งที่ใช้ลิสต์คอมพริเฮนชันในตัวอย่างโค้ดข้างต้น sentence เป็นสตริง เราจึงสามารถใช้ .split ในการเปลี่ยนให้สตริง เป็นลิสต์ของคำโดยใช้ช่องว่างเป็นตัวแยก ผลลัพธ์ที่ได้คือ
[['I', 'want', 'you'], ['I', 'need', 'you'], ['I', 'love', 'you']]
ซึ่งเป็นลิสต์ของลิสต์ของสตริง
คำถามชวนคิด
สมมติว่าเรามีข้อมูลต่อไปนี้
list_sen = [['แซม','ซื้อ','tv','ใหม่'],['android', 'ไม่', 'ได้','ถูก', 'กว่า', 'iphone']]
list_lang = [['th','th','en','th'],['en', 'th', 'th','th', 'th', 'en']]
list_lang2 = [[False, False, True, False], [True, False, False, False, False, True]]
list_len = [[3, 4, 2, 4], [7, 3, 3, 3, 4, 6]]
คำสั่งต่อไปนี้คืนค่าเป็นอะไร ซึ่งจัดเป็นข้อมูลประเภทใด
list_sen[0]list_lang[1][0]list_lang2[1][2]list_len[0][3]
เฉลย
คำสั่ง |
คืนค่า |
ประเภทข้อมูล |
คำอธิบาย |
|---|---|---|---|
|
|
ลิสต์ของสตริง |
|
|
|
สตริง |
|
|
|
บูลีน |
|
|
|
จำนวนเต็ม |
|
รูปแบบการใช้งานที่พบเห็นเป็นประจำ ในการประมวลผลข้อมูล ได้แก่
ไล่วนซ้ำบนสมาชิกทุกตัวที่อยู่ในลิสต์ย่อย
รันฟังก์ชันไปบนสมาชิกทุกตัวที่อยู่ในลิสต์ย่อย
ทำลิสต์ให้แบนเรียบ (flatten)
ไล่วนซ้ำบนสมาชิกทุกตัวที่อยู่ในลิสต์ย่อย#
สมมติว่าเราต้องให้นับจำนวนคำในประโยคที่เก็บไว้ในลิสต์ของลิสต์ของสตริง เราต้องใช้วงวนฟอร์เพื่อไล่ลิสต์ย่อยออกมาทีละตัว และแต่ในลิสต์ย่อยเราต้องใช้วงวนฟอร์อีกชั้นหนึ่งเพื่อไล่สตริงออกมาทีละคำ แปลออกมาเป็นโค้ดเทียมได้ดังนี้
for ลิสต์ย่อย in ลิสต์ใหญ่
for ข้อมูลเดี่ยว in ลิสต์ย่อย
ทำอะไรกับข้อมูลเดี่ยว
ตัวอย่างที่ 1#
สมมติว่าเราต้องการนับจำนวนคำทั้งหมดที่อยู่ในชุดข้อมูล โดยข้อมูลที่ได้มาถูกจัดเก็บในลิสต์ของประโยค และแต่ละประโยคถูกจัดเก็บในรูปของลิสต์ของสตริง ดังนั้นโครงสร้างข้อมูลที่ได้รับมาคือ ลิสต์ของลิสต์ของสตริง ดังนี้
sentences = [['I', 'want', 'you'], ['I', 'need', 'you'], ['I', 'love', 'you']]
total_words = 0
for sentence in sentences:
for word in sentence:
total_words += 1
print(total_words)
สิ่งที่ปรากฏบนหน้าจอ คือ
9
ซึ่งเป็นจำนวนคำทั้งหมดในลิสต์ของลิสต์ของสตริง
โปรแกรมข้างต้นมีการใช้วงวนฟอร์ซ้อนกัน (double for loop) ที่มีวงวนฟอร์ชั้นนอก และชั้นใน
วงวนฟอร์ชั้นนอกเป็นการไล่เอาสมาชิกแต่ละตัวที่เป็นลิสต์ออกมาจากลิสต์ของลิสต์ (
sentences) โดยในแต่ละรอบให้ใช้ตัวแปรsentenceมาใช้เก็บลิสต์ย่อยวงวนฟอร์ชั้นในเป็นการไล่เอาสมาชิกแต่ละตัวที่เป็นสตริงออกมาจากลิสต์ของสตริง (
sentence) โดยในแต่ละรอบให้ใช้ตัวแปรwordมาใช้เก็บสตริง และในแต่ละรอบให้นับคำที่อยู่ในตัวแปรwordแล้วบวกเพิ่มในตัวแปรtotal_wordsที่เป็นจำนวนคำทั้งหมด
ตัวอย่างที่ 2#
สมมติว่าเราต้องการหาคำที่สะกดด้วยตัวอักษรภาษาอังกฤษทั้งหมดโดยไม่ต้องนับตัวซ้ำ ข้อมูลที่ได้มาถูกจัดเก็บอยู่ในลิสต์ของลิสต์ของสตริงคำ เช่นเดียวกันกับตัวอย่างที่ 1
list_sen = [['แซม','ซื้อ','tv','ใหม่'],['android', 'ไม่', 'ได้','ถูก', 'กว่า', 'iphone']]
eng_word_set = set()
for sen in list_sen:
for word in sen:
if word.isalpha():
eng_word_set.add(word)
วงวนฟอร์ชั้นนอกเป็นการไล่เอาสมาชิกแต่ละตัวที่เป็นลิสต์ออกมาจากลิสต์ของลิสต์ (list_sen) โดยในแต่ละรอบให้ใช้ตัวแปร sen มาใช้เก็บลิสต์ย่อย และวงวนฟอร์ชั้นในเป็นการไล่เอาสมาชิกแต่ละตัวที่เป็นสตริงออกมาจากลิสต์ของสตริง (sen) โดยในแต่ละรอบให้ใช้ตัวแปร word มาใช้เก็บสตริง และในแต่ละรอบให้ตรวจสอบว่าสตริงที่อยู่ในตัวแปร word เป็นสตริงที่มีแต่ตัวอักษรภาษาอังกฤษหรือไม่ โดยใช้เมท็อดของสตริง .isalpha() ซึ่งจะคืนค่าเป็นบูลีน ถ้าเป็นค่า True ให้เพิ่มสตริงที่อยู่ในตัวแปร word ลงในเซ็ต eng_word_set โดยใช้คำสั่ง eng_word_set.add(word) ซึ่งเป็นการเพิ่มสตริงลงในเซ็ต และเนื่องจากเราใช้เซ็ตในการเก็บ สตริงที่ซ้ำกันจะถูกลบออกไปโดยอัตโนมัติ
รันฟังก์ชันไปบนสมาชิกทุกตัวที่อยู่ในลิสต์ย่อย#
การรันฟังก์ชันไปบนสมาชิกทุกตัว เราเรียกว่าการแปลงส่งฟังก์ชัน หรือการแม็ปฟังก์ชัน ให้ลองนึกทบทวนถึงการแม็ปฟังก์ชันกับลิสต์ที่ไม่มีการซ้อนลิสต์ จากตัวอย่างต่อไปนี้
สมมติว่า เราต้องการแม็ปฟังก์ชันด้วยฟังก์ชันยกกำลังสองไปบนลิสต์ของตัวเลข numbers = [2, 10, 12, 20] (ซึ่งเป็นลิสต์ที่ยังไม่มีการซ้อนลิสต์) เริ่มจากการสร้างฟังก์ชัน square ที่รับตัวเลขเข้ามา แล้วคืนค่ากลับมาเป็นค่าที่ยกกำลังสอง
def square(x):
return x ** 2
เราอยากได้ผลลัพธ์จากการรัน square ไปทุกตัวบนลิสต์ numbers
results = [square(2), square(10), square(12), square(20)]
หรือ
results = [square(numbers[0]), square(numbers[1]), square(numbers[2]), square(numbers[3])]
แต่เนื่องจากเราไม่ทราบล่วงหน้าว่าลิสต์ numbers มีสมาชิกกี่ตัว เราจึงต้องเขียนโค้ดให้สามารถรัน square ไปบนสมาชิกทุกตัวของลิสต์ numbers ได้โดยไม่ต้องระบุจำนวนรอบของวงวนฟอร์ไว้ล่วงหน้า เราจึงจำเป็นต้องแม็ปฟังก์ชัน ซึ่งมี 3 วิธี ดังนี้
วงวนฟอร์ซ้อนวงวนฟอร์: ใช้วงวนฟอร์แล้วเก็บผลลัพธ์ไว้ในลิสต์ที่ขึ้นมาเตรียมไว้
results = [] for ข้อมูลเดี่ยว in ลิสต์: ผลลัพธ์ = ฟังก์ชัน(ข้อมูลเดี่ยว) results.append(ผลลัพธ์)
ตัวอย่าง เช่น
numbers = [2, 10, 12, 20] results = [] for number in numbers: results.append(square(number)) print(results)
ผลลัพธ์ที่จะแสดงผลบนหน้าจอ คือ
[4, 100, 144, 400]
ลิสต์คอมพริเฮนชัน
results = [ฟังก์ชัน(ข้อมูลเดี่ยว) for ข้อมูลเดี่ยว in ลิสต์]
ตัวอย่าง เช่น
numbers = [2, 10, 12, 20] results = [square(number) for number in numbers]
ฟังก์ชัน
map: เป็นฟังก์ชันที่ใช้สำหรับการนำฟังก์ชันหนึ่งมาประยุกต์ใช้กับสมาชิกแต่ละตัวของคอลเลคชันที่ให้มา เช่น ลิสต์ ดิกชันนารี เซต โดยฟังก์ชันmapจะคืนค่าเป็น “map object” ซึ่งสามารถแปลงเป็นลิสต์ ด้วยการใช้คำสั่งlist()เพื่อให้สามารถดูผลลัพธ์ได้ในรูปแบบลิสต์โครงสร้างการใช้งาน
mapมีดังนี้results = list(map(ฟังก์ชัน, ลิสต์))
ตัวอย่าง เช่น
numbers = [2, 10, 12, 20] results = list(map(square, numbers))
เราสามารถใช้วิธีเหล่านี้ในทำนองเดียวกันเพื่อแม็ปฟังก์ชันกับลิสต์ของลิสต์
วงวนซ้อนวงวน#
โครงสร้างของการใช้วงวนฟอร์เพื่อแม็ปฟังก์ชันไปบนลิสต์ซ้อนลิสต์ จะต้องมีการใช้วงวนซ้อนวงวน (nested for loop) ซึ่งมีโครงสร้างดังนี้
results = []
for ลิสต์ย่อย in ลิสต์ใหญ่:
sub_results = []
for ข้อมูลเดี่ยว in ลิสต์ย่อย:
ผลลัพธ์ = ฟังก์ชัน(ข้อมูลเดี่ยว)
sub_results.append(ผลลัพธ์)
results.append(sub_results)
จุดที่ซับซ้อนและน่าสังเกตคือ การสร้างลิสต์ย่อย sub_results ขึ้นมาเพื่อเก็บผลลัพธ์ที่ได้จากการแม็ปฟังก์ชันกับสมาชิกแต่ละตัวในลิสต์ย่อย ถ้าเราแกะเอาวงวน ชั้นนอกออกเราก็จะเห็นว่าโครงสร้างนั้นเหมือนกับการแม็ปฟังก์ชันบนลิสต์ที่ไม่มีการซ้อนลิสต์
sub_results = []
for ข้อมูลเดี่ยว in ลิสต์ย่อย:
ผลลัพธ์ = ฟังก์ชัน(ข้อมูลเดี่ยว)
sub_results.append(ผลลัพธ์)
แต่เพราะว่าเราต้องการแม็ปฟังก์ชันไปบนลิสต์ย่อยทุกลิสต์ เราจึงต้องเอาโค้ดก้อนนี้ซ้อนเข้าไปในวงวนฟอร์ชั้นนอก 1 ชั้น
ตัวอย่าง
สมมติว่าเราต้องการหาความยาวของคำแต่ละคำในประโยคที่เก็บไว้ในลิสต์ของลิสต์ของสตริง เช่น ถ้าหาก input คือ
words = [['แซม','ซื้อ','tv','ใหม่'],['android', 'ไม่', 'ได้','ถูก', 'กว่า', 'iphone']]
โปรแกรมจะต้องคืนค่ามาเป็นลิสต์ของลิสต์ของตัวเลข ซึ่งตัวเลขแต่ละตัวคือความยาวของคำในแต่ละตำแหน่ง
[[3, 4, 2, 4], [7, 3, 3, 3, 4, 6]]
โจทย์ข้อนี้เราทราบแล้วว่าเราต้องมีการแม็ปฟังก์ชันโดยใช้คำสั่ง len ลงบนสมาชิกแต่ละตัวในลิสต์ย่อย ดังนั้นเราสามารถใช้โครงสร้างวงวนซ้อนวงวนมาประกอบกันได้ดังนี้
words = [['แซม','ซื้อ','tv','ใหม่'],['android', 'ไม่', 'ได้','ถูก', 'กว่า', 'iphone']]
lengths = []
for sen in words:
sub_lengths = []
for word in sen:
sub_lengths.append(len(word))
lengths.append(sub_lengths)
print(lengths)
ลิสต์คอมพริเฮนชันซ้อนใน#
เราสามารถใช้ลิสต์คอมพริเฮนชันซ้อนใน (nested list comprehension) ในการแม็ปฟังก์ชันได้ดังนี้
results = [[ฟังก์ชัน(ข้อมูลเดี่ยว) for ข้อมูลเดี่ยว in ลิสต์ย่อย] for ลิสต์ย่อย in ลิสต์ใหญ่]
สังเกตว่าเราซ้อนนิพจน์ [ฟังก์ชัน(ข้อมูลเดี่ยว) for ข้อมูลเดี่ยว in ลิสต์ย่อย] เข้าไปใน [นิพจน์ for ลิสต์ย่อย in ลิสต์ใหญ่]
ตัวอย่าง
words = [['แซม','ซื้อ','tv','ใหม่'],['android', 'ไม่', 'ได้','ถูก', 'กว่า', 'iphone']]
lengths = [[len(word) for word in sen] for sen in words]
print(lengths)
ทำลิสต์ให้แบนเรียบ#
การทำลิสต์ให้แบนเรียบ (flatten) คือ การเปลี่ยนลิสต์ที่เคยเป็นลิสต์ซ้อนลิสต์ให้เป็นลิสต์ธรรมดาที่เก็บข้อมูลเดี่ยวไว้ ในกรณีที่ข้อมูลที่เราได้รับมาเป็นข้อมูลที่มีโครงสร้างที่ซับซ้อนเกินไปอย่างลิสต์ของลิสต์ของคำซึ่งเก็บข้อมูลระดับประโยคไว้ด้วยว่ามีประโยคอยู่กี่ประโยค (ลิสต์ย่อย) และแต่ละประโยคมีคำอยู่กี่คำ (สตริงที่อยู่ในลิสต์ย่อย) หากเราไม่ต้องการข้อมูลในระดับประโยคเราอาจจะย่อลงให้เหลือเพียงลิสต์ของสตริงคำ โดยการทำลิสต์ให้เรียบ
โครงสร้างของโค้ดที่ใช้ในการทำลิสต์ให้เรียบ จะมีการใช้วงวนฟอร์ซ้อนวงวนฟอร์ซึ่งมีโครงสร้างดังนี้
results = []
for ลิสต์ย่อย in ลิสต์ใหญ่:
for ข้อมูลเดี่ยว in ลิสต์ย่อย:
results.append(ข้อมูลเดี่ยว)
หรือ จะใช้ลิสต์คอมพริเฮนชันซ้อนกันในการทำลิสต์ให้เรียบแบน ดังนี้
results = [ข้อมูลเดี่ยว for ลิสต์ย่อย in ลิสต์ใหญ่ for ข้อมูลเดี่ยว in ลิสต์ย่อย]
สังเกตว่าโครงสร้างลิสต์คอมพริเฮนชันซ้อนในแบบนี้มีลักษณะคล้ายคลึงกับ การแม็ปฟังก์ชันบนลิสต์ซ้อนในซึ่งมีโครงสร้างดังนี้
results = [[ฟังก์ชัน(ข้อมูลเดี่ยว) for ข้อมูลเดี่ยว in ลิสต์ย่อย] for ลิสต์ย่อย in ลิสต์ใหญ่]
ข้อแตกต่าง คือนิพจน์ที่ใช้ในการทำลิสต์ให้เรียบมีอยู่ตำแหน่งเดียวเท่านั้น และไม่มีการใช้ฟังก์ชันใด ๆ ในการประมวลผลข้อมูล แต่ว่าลิสต์คอมพริเฮนชันซ้อนในสำหรับการแม็ปฟังก์ชันจะมีนิพจน์สำหรับวงวนฟอร์ชั้นนอกคือ [ฟังก์ชัน(ข้อมูลเดี่ยว) for ข้อมูลเดี่ยว in ลิสต์ย่อย] ซึ่งให้ค่าเป็นลิสต์ และนิพจน์สำหรับวงวนฟอร์ชั้นในคือ ฟังก์ชัน(ข้อมูลเดี่ยว)
ข้อแตกต่างของโครงสร้างอีกอย่างคือลิสต์คอมพริเฮนชันซ้อนในสำหรับทำให้ลิสต์ให้เรียบ จะมีการใช้วงวนฟอร์ชั้นนอกก่อน และวงวนฟอร์ชั้นในทีหลัง แต่สำหรับการแม็ปฟังก์ชันจะมีการใช้วงวนฟอร์ชั้นในก่อน และวงวนฟอร์ชั้นนอกหลัง

ตัวอย่าง
words = [['แซม','ซื้อ','tv','ใหม่'],['android', 'ไม่', 'ได้','ถูก', 'กว่า', 'iphone']]
flattened_word_list = [word for sen in words for word in sen]
print(flattened_word_list)
ผลลัพธ์ที่ได้คือ
['แซม', 'ซื้อ', 'tv', 'ใหม่', 'android', 'ไม่', 'ได้', 'ถูก', 'กว่า', 'iphone']
ลิสต์ของทูเปิล#
ทูเปิลเป็นโครงสร้างข้อมูลที่เหมาะกับการเก็บข้อมูลหนึ่งหน่วยที่มีหลายมิติ เช่น พิกัด 1 พิกัด มีค่า x และ y ซึ่งเป็นตัวเลข 2 ค่า เช่น
coordinate = (3, 4)
หรือ คน 1 คน มีชื่อ และนามสกุล และชื่อเล่นซึ่งเป็นสตริง 3 สตริง เช่น
person_name = ('เศรษฐา', 'ทวีสิน', 'นิด')
เราใช้ลิสต์ของทูเปิลเวลาเราต้องการเก็บพิกัดหลาย ๆ พิกัด หรือชื่อนักเรียนหลาย ๆ คน เช่น
coordinates = [(3, 4), (5, 6), (7, 8)]
names = [('เศรษฐา', 'ทวีสิน', 'นิด'), ('ประยุทธ์', 'จันทร์โอชา', 'ตู่'), ('ยิ่งลักษณ์', 'ชินวัตร', 'ปู'), ('อภิสิทธิ์', 'เวชชาชีวะ', 'มาร์ค')]
ถ้าหากเราต้องการให้โค้ดดูอ่านง่ายขึ้น เราควรจัดรูปให้สมาชิกแต่ละตัวของลิสต์อยู่แยกบรรทัดกัน
coordinates = [
(3, 4),
(5, 6),
(7, 8)
]
names = [
('เศรษฐา', 'ทวีสิน', 'นิด'),
('ประยุทธ์', 'จันทร์โอชา', 'ตู่'),
('ยิ่งลักษณ์', 'ชินวัตร', 'ปู'),
('อภิสิทธิ์', 'เวชชาชีวะ', 'มาร์ค')
]
เมื่อเราแจกแจงโครงสร้างดังโค้ดข้างต้น เราจะสังเกตได้ว่าข้อมูลที่เก็บอยู่ในตัวแปร names มีลักษณะดังนี้
โครงสร้างข้อมูลชั้นนอกสุดเป็นลิสต์ เพราะว่าข้อมูลถูกครอบอยู่ด้วย
[]โครงสร้างข้อมูลชั้นในที่เป็นสมาชิกแต่ละตัวของลิสต์เป็นทูเปิล เพราะว่าข้อมูลถูกครอบอยู่ด้วย
()ข้อมูลเดี่ยวชั้นในสุดเป็นสตริงเพราะมีการใช้
''
คำถามชวนคิด
สมมติว่าเรามีข้อมูลต่อไปนี้
cities = [(37.774929, -122.419418), (13.756331, 100.501762)]
คำสั่งต่อไปนี้คืนค่าเป็นอะไร
cities[0]cities[1][0]
เฉลย
คำสั่ง |
คืนค่า |
ประเภทข้อมูล |
คำอธิบาย |
|---|---|---|---|
|
|
ทูเปิล |
|
|
|
float |
|
ไล่วนซ้ำสมาชิกทุกตัวที่อยู่ในลิสต์ของทูเปิล#
เราสามารถไล่เข้าถึงสมาชิกทุกตัวที่อยู่ในลิสต์ของทูเปิลได้ด้วยวิธีเดียวกันกับการไล่บนลิสต์ของข้อมูลประเภทอื่น ๆ โดยใช้วงวนฟอร์เช่นเดิม ดังนี้
for ทูเปิล in ลิสต์ของทูเปิล:
ทำอะไรกับทูเปิล
สมมติว่าเรามีลิสต์ของพิกัดละติจูดและลองจิจูดของเมือง และเราต้องการสร้างอีกลิสต์เพื่อเก็บเฉพาะเมืองที่อยู่ซีกโลกตะวันตก โดยใช้วงวนฟอร์ดังนี้
cities = [(37.774929, -122.419418), (13.756331, 100.501762)]
western_cities = []
for city in cities:
if city[1] < 0:
western_cities.append(city)
หรือใช้ลิสต์คอมพริเฮนชัน
cities = [(37.774929, -122.419418), (13.756331, 100.501762)]
western_cities = [city for city in cities if city[1] < 0]
เวลาเราวนซ้ำบนลิสต์ของทูเปิล ปัญหาที่เรามักจะพบคือเราอาจจะลืมว่าสมาชิกแต่ละตัวของทูเปิลเก็บค่าอะไรอยู่ เช่น เราอาจจะลืมว่า city[0] เก็บละติจูดหรือลองจิจูด ทำให้เราเขียนโปรแกรมผิดพลาดได้ง่าย ด้วยเหตุนี้เรานิยมขยายทูเปิลออก (unpack tuple) หรือกระจายค่าแต่ละค่าของทูเปิลแยกออกมาเก็บไว้ในตัวแปรแต่ละตัวก่อน แล้วจึงใช้ตัวแปรเหล่านั้นในการประมวลผลข้อมูล
จากตัวอย่างข้างต้นเราควรแก้ไขโค้ดให้อ่านง่ายขึ้นด้วยการกระจายค่าของทูเปิลออกมาเก็บไว้ในตัวแปรแต่ละตัวก่อน ดังนี้
cities = [(37.774929, -122.419418), (13.756331, 100.501762)]
western_cities = []
for city in cities:
lat, lon = city
if lon < 0:
western_cities.append((lat, lon))
หรือกระจายค่าของทูเปิลออกมาเก็บไว้ในตัวแปรในวงวนฟอร์โดยไม่ต้องสร้างแปรมาเก็บทูเปิลเลย
cities = [(37.774929, -122.419418), (13.756331, 100.501762)]
western_cities = []
for lat, lon in cities:
if lon < 0:
western_cities.append((lat, lon))
หรือใช้ลิสต์คอมพริเฮนชัน
results = [นิพจน์ for ตัวแปร1, ตัวแปร2, ... , ตัวแปร n in ลิสต์ของทูเปิล]
เราสามารถแก้ไขโค้ดเป็น
cities = [(37.774929, -122.419418), (13.756331, 100.501762)]
western_cities = [(lat,lon) for lat, lon in cities if lon < 0]
หากเราต้องการขยายทูเปิลออก เราต้องทราบจำนวนสมาชิกของทูเปิลที่อยู่ในลิสต์ และทูเปิลทุกตัวที่อยู่ในลิสต์จะต้องมีจำนวนสมาชิกเท่ากัน ถ้าหากจำนวนตัวแปรที่เราใช้น้อยกว่าจำนวนสมาชิกของทูเปิล จะเกิดความผิดพลาดขึ้น และถ้าหากจำนวนตัวแปรที่เราใช้มากกว่าจำนวนสมาชิกของทูเปิล จะเกิดความผิดพลาดขึ้นเช่นกัน
cities = [(37.774929, -122.419418), (13.756331, 100.501762)]
western_cities = []
for city in cities:
latitude, longitude, height = city
if longitude < 0:
western_cities.append(city)
เราจะได้ผลลัพธ์เป็น
ValueError: not enough values to unpack (expected 3, got 2)
เนื่องจากเราขยายทูเปิลออกไปยังตัวแปรสามตัวแปร แต่ว่าสมาชิกของทูเปิลมีเพียงสองตัว ภาษาไพทอนไม่ยอมให้ height เป็นค่า None เพื่อให้โปรแกรมดำเนินต่อไปได้ จึงแจ้ง ValueError ออกมา
หากทูเปิลแต่ละตัวมีจำนวนสมาชิกที่แตกต่างกัน
cities = [(37.774929, -122.419418, 100), (13.756331, 100.501762)]
western_cities = []
for city in cities:
latitude, longitude, height = city
if longitude < 0:
western_cities.append(city)
เราจะได้ผลลัพธ์เป็นข้อผิดพลาดขึ้นมาเหมือนกัน
ValueError: not enough values to unpack (expected 3, got 2)
เพราะว่าเมื่อเราวนซ้ำไปถึงทูเปิล (13.756331, 100.501762) จำนวนตัวแปรที่เตรียมไว้ยังคงมีสามตัวเช่นเดิม แต่ว่าสมาชิกของทูเปิลมีสองตัวเท่านั้น
จากโค้ดข้างเราสังเกตได้ว่าค่าของ latitude ไม่ได้ถูกใช้ในการประมวลผลข้อมูลเลย แต่เราจำเป็นต้องสร้างตัวแปรเข้ามารองรับค่าทุกค่าของทูเปิล ในกรณีดังกล่าวเรามีธรรมเนียมปฏิบัติ (convention) ว่าจะตั้งชื่อตัวแปรที่ไม่ได้ใช้เป็น _ เพื่อบ่งบอกว่าตัวแปรนั้นตั้งมาเพื่อรับค่าไม่ให้เกิดข้อผิดพลาด แต่ไม่ได้นำไปประมวลผลต่อ ดังนั้นเราสามารถแก้ไขโค้ดจากตัวอย่างเป็น
cities = [(37.774929, -122.419418), (13.756331, 100.501762)]
western_cities = []
for city in cities:
_, longitude = city
if lon < 0:
western_cities.append(city)
จากตัวอย่างทั้งหมดนี้ทำให้เห็นว่าการเขียนโค้ดเพื่อประมวลผลข้อมูลที่มีความซับซ้อนมากขึ้นมีอยู่หลายวิธี นอกจากเราต้องเขียนโค้ดให้ประมวลผลได้ผลลัพท์ถูกต้องแล้ว เรายังต้องคำนึงถึงว่าโค้ดที่เราเขียนนั้นจะอ่านง่ายและเข้าใจได้ง่าย โดยไม่ต้องใช้เวลานานในการอ่าน และหาข้อผิดพลาดที่เกิดขึ้นในโค้ด
ลิสต์ของดิกชันนารี#
ลิสต์ของดิกชันนารีเป็นโครงสร้างข้อมูลอีกประเภทที่พบเห็นได้บ่อย เราอาจจะสงสัยกันว่าในกรณีใดที่เราจำเป็นต้องเก็บลิสต์ของสิ่งที่เก็บคู่คีย์แวลูเอาไว้หลาย ๆ คู่ ดิกชันนารีที่ถูกเก็บอยู่ในลิสต์มักจะเป็นดิกชันนารีที่มีชุดของคีย์ที่เหมือนกันในทุกดิกชันนารี ดิกชันนารีประเภทนี้อันทีจริงแล้วทำหน้าที่คล้ายคลึงกับทูเปิล เช่น หากเราใช้ลิสต์ของทูเปิลในการเก็บข้อความและผู้ส่งข้อความดังนี้
messages = [
('โกโก้', 'แม่เป็นกำลังใจของหนู')
('โกโก้', 'หนูมีแม่คนเดียว'),
('คริส', 'ทุกคนมีแม่คนเดียวโกโก้')
]
การเก็บข้อมูลในลักษณะนี้อาจทำให้เกิดข้อผิดพลาดได้ตรงที่เราอาจจะลืมว่าเราเก็บชื่อคนพูดไว้ในตำแหน่งใดของทูเปิล ในกรณีเราอาจจะใช้ดิกชันนารีแทนได้เพื่อความชัดเจน
messages = [
{'speaker': 'โกโก้', 'message': 'แม่เป็นกำลังใจของหนู'},
{'speaker': 'โกโก้', 'message': 'หนูมีแม่คนเดียว'},
{'speaker': 'คริส', 'message': 'ทุกคนมีแม่คนเดียวโกโก้'}
]
โดยผิวเผินแล้วการเก็บข้อมูลทั้งสองวิธีนั้นเก็บข้อมูลได้ครบถ้วนเหมือนกัน ให้ลองเปรียบเทียบโค้ดในการแสดงผลข้อความให้ดูเป็นบทสนทนา
for m in messages:
print(f'{m[0]}: {m[1]}')
กับ
for m in messages:
print(f'{m["speaker"]}: {m["message"]}')
จากตัวอย่างข้างต้นเราสามารถสังเกตได้ว่าการใช้ดิกชันนารีทำให้โค้ดอ่านง่ายขึ้น และเราไม่ต้องคอยจำลำดับของข้อมูลในทูเปิล แต่ก็มีข้อควรระวังคือ ดิกชันนารีทุกตัวที่อยู่ในลิสต์จะต้องมีคีย์ที่เหมือนกันหมด มิฉะนั้นเราจะต้องเขียนโค้ดเพิ่มเติมเพื่อตรวจสอบว่าดิกชันนารีมีคีย์ที่ต้องการเข้าถึงหรือไม่ ซึ่งอาจจะทำให้โค้ดดูซับซ้อนเกินความจำเป็น
ดิกชันนารีที่เราใช้ลักษณะดังตัวอย่างข้างต้น จะมีคีย์ที่เป็นสตริงที่เป็นเขตข้อมูล หรือฟีลด์ (field) บ่งบอกว่าข้อมูลที่เป็น แวลูเป็นข้อมูลอะไร เช่น ดิกชันนารีในตัวอย่างข้างต้นมี 2 ฟีลด์ คือ speaker และ message ซึ่งบ่งบอกว่าแวลูของดิกชันนารีคือผู้พูด และข้อความที่คนนั้นพูด เราขอเรียกดิกชันนารีที่มีคีย์เป็นฟีลด์ว่า ดิกชันนารีคู่ฟีลด์แวลู (field-value dictionary)
ตัวอย่างที่แล้วอาจจะยังไม่ได้ทำให้เห็นภาพว่าเหตุใดเราจึงจำเป็นต้องใช้ดิกชันนารีคู่ฟีลด์แวลู ให้ลองพิจารณากรณีที่เราต้องเก็บทวิตจำนวนมาก
[ {'id': 'BarackObama', 'date': 'October 17, 2019', 'num comments': 243000,
'num retweets': 37200, 'num fav': 250300, 'text': 'I was proud to work with Justin Trudeau as President'},
{'id': 'SpeakerPelosi', 'date': 'October 17, 2019', 'num comments': 22700,
'num retweets': 10000, 'num fav': 45600, 'text': 'What courage does it take to pass legislation that will save lives?'},
{'id': 'BarackObama', 'date': 'October 15, 2019', 'num comments': 2000,
'num retweets': 5400, 'num fav': 52800, 'text': 'In December, Michelle and I will head to Malaysia for the first @ObamaFoundation Leaders: Asia-Pacific gathering'}
]
ดิกชันนารีที่เราใช้ในตัวอย่างข้างต้นเป็น ดิกชันนารีคู่ฟีลด์แวลู ที่มีฟีลด์ดังต่อไปนี้
idบ่งบอกว่าทวิตนั้นมาจากบัญชีใครdateบ่งบอกว่าทวิตนั้นถูกโพสต์เมื่อวันที่ไหนnum commentsบ่งบอกว่าทวิตนั้นมีคอมเมนต์กี่คอมเมนต์num retweetsบ่งบอกว่าทวิตนั้นถูกรีทวิตกี่ครั้งnum favบ่งบอกว่าทวิตนั้นทำให้เป็น favorite โดยการกดปุ่มหัวใจบนแอปกี่ครั้งtextบ่งบอกว่าทวิตนั้นมีข้อความอะไร
สมมติต่ออีกว่าเราต้องการเขียนโปรแกรมเพื่อหาว่าแต่ละคนถูกรีทวิตทั้งหมดกี่ครั้ง
import collections
counter = collections.Counter()
for tweet in tweet_list:
twitter_id = tweet['id']
retweets = tweet['num retweets']
counter[twitter_id] += retweets
print(counter.most_common())
ผลลัพธ์ที่ได้คือ
[('BarackObama', 42600), ('SpeakerPelosi', 10000)]
ถ้าหากเราต้องการทำเหมือนกันด้วยการใช้ลิสต์ของทูเปิล โค้ดจะมีความซับซ้อนขึ้น และอ่านยากขึ้น อย่างแรกคือผู้เขียนโค้ดจะต้องไปตามหาว่าชื่อทวิตเตอร์ และจำนวนการรีทวิตอยู่ในตำแหน่งใดของทูเปิล ทำให้เกิดความยุ่งยากในการเขียนโค้ด เมื่อเขียนเสร็จแล้วโค้ดก็จะอ่านทำความเข้าใจได้ยาก ดังที่เห็นในโปรแกรมข้างล่างนี้
counter = collections.Counter()
for tweet in tweet_list:
twitter_id = tweet[0]
retweets = tweet[3]
counter[twitter_id] += retweets
หากเราต้องกลับมาอ่านโค้ดของเราเอง เราก็อาจจะลืมไปแล้วว่าตำแหน่งที่ 0 และ 3 เก็บอะไรไว้อยู่ หรือถ้าส่งต่อให้ผู้อื่นในทีมเพื่อตรวจสอบหรือเขียนโค้ดต่อจากเรา ก็จะเข้าใจยากด้วยเหตุผลเดียวกัน ปัญหาอีกประการหนึ่งคือ ถ้าหากเพิ่มข้อมูลเข้าไปในทูเปิลก็อาจจะทำให้ตำแหน่งที่เก็บเปลี่ยนไปได้ เนื่องจากทูเปิลเป็นโครงสร้างข้อมูลแบบมีลำดับ จากตัวอย่างนี้ทำให้เห็นว่าถ้าหากข้อมูลหนึ่งตัวเก็บข้อมูลอยู่หลายอย่างในลักษณะคล้ายกับกับการกรอกฟอร์มที่มีหลาย ๆ ฟีลด์ การใช้ดิกชันนารีคู่ฟีลด์แวลูเป็นวิธีที่ดีกว่าการใช้ทูเปิล
ดิกชันนารีที่คีย์เป็นทูเปิล#
จากบทที่แล้วชนิดของข้อมูลที่สามารถเป็นคีย์ในดิกชันนารีได้ล้วนแต่เป็นข้อมูลเดี่ยว เช่น ตัวเลข หรือสตริง ดิกชันนารีในภาษาไพทอนอนุญาตให้ใช้ทูเปิลที่เก็บตัวเลขหรือสตริงเป็นคีย์ได้ ทำให้มีความยืดหยุ่นในการเก็บข้อมูลมากขึ้น ดังตัวอย่างต่อไปนี้
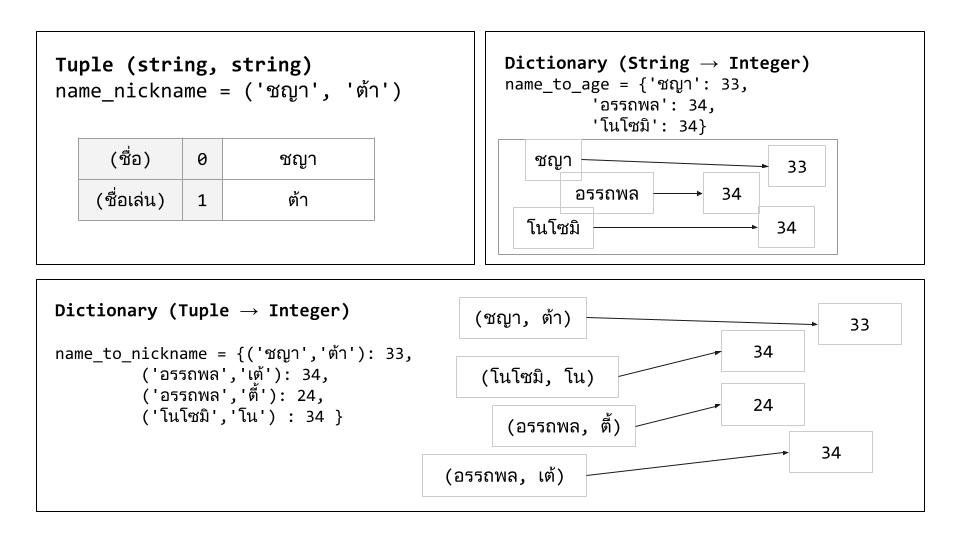
ภาพที่ 14 ภาพอธิบายโครงสร้างของดิกชันนารี#
จากภาพบนสองภาพจะเห็นได้ว่าเรามีทูเปิลของสตริงสองตำแหน่งไว้เก็บชื่อและชื่อเล่น มีดิกชันนารีรูปแบบที่เคยพบในบทก่อน ๆ คือมีคีย์เป็นสตริง และมีดิกชันนารีรูปแบบใหม่ที่มีคีย์เป็นทูเปิล
หากเราต้องการดิกชันนารีไว้เก็บข้อมูลชื่อคนแล้วพบกรณีที่บางคนชื่อซ้ำกัน เช่น มีคนชื่อ อรรถพล 2 คน การใช้ดิกชันนารีรูปแบบเดิมที่มีคีย์เป็นสตริงในการเก็บข้อมูลโดยเพิ่มสมาชิกใหม่เข้าไปจะทำให้คีย์แวลูเดิมถูกเขียนทับไป เนื่องจากคีย์ในดิกชันนารีห้ามซ้ำกัน
ดังนั้นดิกชันนารีที่มีคีย์เป็นทูเปิลจึงเป็นทางแก้ปัญหานี้ ทำให้เราสามารถใส่ข้อมูลสมาชิกได้เพิ่มขึ้น จากตัวอย่างคือเปลี่ยนรูปแบบดิกชันนารีจากที่มีคีย์เป็นสตริงไว้เก็บชื่ออย่างเดียว ให้เป็นดิกชันนารีที่มีคีย์เป็นทูเปิลไว้เก็บสตริงสองตัวเป็นชื่อกับชื่อเล่นเพื่อเลี่ยงการที่มีคีย์ซ้ำกัน
สมมติว่าเราต้องการเก็บข้อมูลทำสมุดโทรศัพท์มีตัวอย่างโครงสร้างข้อมูลแบบต่าง ๆ ดังนี้
entry_list = [ ('Mark', 'Wahlberg', '111-222-3333'),
('Jane', 'Doe', '222-333-4444'),
('Jane', 'Eyre', '333-444-5555')
]
friend_to_phone = { ('Mark', 'Wahlberg') : '111-222-3333',
('Jane', 'Doe'): '222-333-4444',
('Jane', 'Eyre'): '333-444-5555'
}
ตัวแปร entry_list มีโครงสร้างข้อมูลเป็นลิสต์ของทูเปิลโดยที่ทูเปิลเก็บข้อมูลชื่อ นามสกุล และเบอร์โทรศัพท์เป็นสตริง วิธีการดึงข้อมูลเบอร์โทรศัพท์จากตัวแปร entry_list มีดังนี้
phone_list = []
for first, last, phone in entry_list:
phone_list.append(phone)
หรือใช้ลิสต์คอมพริเฮนชัน
phone_list = [phone for first, last, phone in entry_list]
ตัวแปร friend_to_phone มีโครงสร้างข้อมูลเป็นดิกชันนารีที่มีคีย์เป็นทูเปิล และมีแวลูเป็นสตริง วิธีการดึงข้อมูลเบอร์โทรจากตัวแปร friend_to_phone มีดังนี้
phone_list = list(friend_to_phone.values())
โครงสร้างข้อมูลที่เลือกใช้มีผลอย่างมากต่อการประมวลผลข้อมูลต่อไป เช่น หากเราต้องการสร้างฟังก์ชันสำหรับค้นหาเบอร์โทรของคนคนหนึ่งจากลิสต์ เราต้องไล่วนซ้ำไปบนลิสต์เพื่อหาชื่อที่ต้องการ ดังนี้
def find_mark_from_list(entry_list):
query = ('Mark', 'Wahlberg')
for entry in entry_list:
first, last, phone = entry
first_last = (first, last)
if query == first_last:
return phone
คำถามชวนคิด
จากโปรแกรมข้างต้น ตัวแปรต่อไปนี้ชนิดข้อมูลเป็นอะไร
entryfirst
เฉลย
ทูเปิล
สตริง
ให้เปรียบเทียบวิธีข้างต้นกับวิธีที่ 2 ซึ่งเราเก็บข้อมูลในดิกชันนารี
def find_mark_from_dict(friend_to_phone):
query = ('Mark', 'Wahlberg')
return friend_to_phone[query]
จะเห็นได้ว่าตัวแปร friend_to_phone ที่มีโครงสร้างข้อมูลเป็นดิกชันนารีที่มีคีย์เป็นทูเปิลสามารถเขียนฟังก์ชันค้นหาเบอร์โทรหรือเขียนดึงข้อมูลเบอร์โทรศัพท์ทั้งหมดได้ง่ายและกระชับกว่า ไม่ต้องทำการขยายทูเปิลออกให้ซับซ้อนเหมือนกับการค้นเบอร์โทรหรือเขียนดึงข้อมูลเบอร์โทรทั้งหมดในตัวแปร entry_list ที่มีโครงสร้างข้อมูลเป็นลิสต์ของทูเปิล
นอกจากนี้ ดิกชันนารียังค้นหาเบอร์โทรศัพท์ได้รวดเร็วกว่าลิสต์ของทูเปิล จะเห็นได้ว่าในฟังก์ชันแรกมีการใช้วงวนฟอร์ซึ่งจะทำให้ช้า เพราะต้องไล่หาทีละตัว โดยเฉพาะเมื่อมีข้อมูลจำนวนมาก แต่ในฟังก์ชันที่สองค้นหาเบอร์โทรจากดิกชันนารี สามารถค้นหาแวลูจากคีย์ข้อมูลได้รวดเร็วโดยไม่ต้องคำถึงจำนวนสมาชิกในดิกชันนารี
แต่ในการใช้ดิกชันนารีเราก็ต้องตัดสินใจก่อนว่าจะค้นหาเบอร์โทรด้วยข้อมูลอะไร จากตัวอย่างจะเป็นการใช้ชื่อนามสกุลในการค้นหา จึงใช้ทูเปิลของสตริงสองตัวที่เป็นชื่อและนามสกุลเป็นคีย์ หากยังไม่รู้ว่าจะใช้ข้อมูลอะไรในการค้นหา ลิสต์ของทูเปิลอาจเป็นตัวเลือกที่ดีกว่า
ดิกชันนารีที่แวลูเป็นลิสต์#
การเก็บข้อมูลทำสมุดโทรศัพท์ในกรณีที่คนหนึ่งคนอาจมีเบอร์โทรศัพท์หลายเบอร์ด้วยโครงสร้างข้อมูลแบบลิสต์ของทูเปิลและดิกชันนารีที่มีแวลูเป็นลิสต์ เขียนได้ดังนี้
entry_list = [ ('Mark', 'Wahlberg', '111-222-3333', '444-555-6666'),
('Jane', 'Doe', '222-333-4444'),
('Jane', 'Eyre', '333-444-5555', '777-555-1111')
]
name_to_phone_list = { ('Mark', 'Wahlberg') : ['111-222-3333', '444-555-6666'] ,
('Jane', 'Doe'): ['222-333-4444'],
('Jane', 'Eyre'): ['333-444-5555', '777-555-1111']
}
การที่บางคนอาจมีเบอร์โทรศัพท์หลายเบอร์จะเป็นปัญหากับตัวแปร entry_list ที่เป็นลิสต์ของทูเปิลในการเปิดหาเบอร์โทรทั้งหมด เนื่องจากทูเปิลแต่ละตัวในลิสต์มีจำนวนสมาชิกไม่เท่ากัน จึงทำให้ไม่สามารถขยายทูเปิลออกแบบเดิมได้ ตัวแปร name_to_phone_list ซึ่งเป็นดิกชันนารีที่มีคีย์เป็น tuple และมีแวลูเป็นลิสต์ของสตริงที่เก็บข้อมูลเบอร์โทรจึงเป็นทางเลือกที่เหมาะสมในกรณีนี้
ตัวอย่างการเขียนโปรแกรมเพื่อค้นหาเบอร์โทรของคนหนึ่งคน
results = []
first_last = ('Mark', 'Wahlberg')
phone_list = name_to_phone_list[first_last]
for phone in phone_list:
results.append(phone)
จากโปรแกรมข้างต้นจะเป็นการค้นหาเบอร์โทรของ Mark Wahlberg จึงใช้คีย์('Mark', 'Wahlberg') ในการเข้าถึงแวลูซึ่งเป็นลิสต์ของสตริงที่เป็นเบอร์โทรด้วยคำสั่ง name_to_phone_list[first_last] จากนั้นใช้วงวนฟอร์วนสตริงแต่ละตัวในลิสต์ของสตริงนั้นโดยใช้ตัวแปร phone มารับค่าสตริงและเพิ่มเข้าไปในลิสต์ผลลัพธ์ของเรา
เราจะได้ผลลัพธ์ลัพธ์ของ results เป็น
['111-222-3333', '444-555-6666']
ในการปรับโค้ดให้เราสามารถเปิดค้นหาเบอร์ของทุกคนได้ เราจะใช้โครงสร้างวงวนซ้อนวงวน โดยเพิ่มวงวนฟอร์ชั้นนอกเข้ากับโค้ดข้างต้น ดังนี้
results = []
first_last_list = list(name_to_phone_list.keys())
for first_last in first_last_list:
phone_list = name_to_phone_list[first_last]
for phone in phone_list:
results.append(phone)
คำถามชวนคิด
จากโปรแกรมข้างต้น คำสั่งต่อไปนี้คืนค่าเป็น type อะไร
name_to_phone_list[first_last]list(name_to_phone_list.keys())
เฉลย
ลิสต์ของสตริง โดยที่สตริงเป็นเบอร์โทร
ลิสต์ของทูเปิล โดยที่ทูเปิลเป็นทูเปิลของสตริงสองตำแหน่งที่เป็นชื่อและนามสกุล
ตัวแปร first_last_list ซึ่งเป็นลิสต์ของทูเปิลจะเก็บคีย์ทั้งหมดของดิกชันนารี name_to_phone_list ไว้ จากนั้น วงวนฟอร์ชั้นนอกจะวนไปที่ลิสต์ของทูเปิลนี้ ใช้ตัวแปร first_last เก็บคีย์ของดิกชันนารีแต่ละตัวไว้ เพื่อนำไปใช้ในคำสั่ง name_to_phone_list[first_last] ในการเรียกคืนค่าแวลูที่เป็นลิสต์ของสตริงที่เก็บเบอร์โทรไว้ และเก็บไว้ในตัวแปร phone_list จากนั้นจะเข้าสู่วงวนฟอร์ชั้นในเหมือนโปรแกรมก่อนหน้า
จากโปรแกรมทั้งหมด สามารถเขียนให้กระชับได้เป็น
results = []
for first_last in name_to_phone_list:
for phone in name_to_phone_list[first_last]:
results.append(phone)
เนื่องจากเวลาวงวนฟอร์ไปบนดิกชันนารี สิ่งที่เราได้ออกมาจะเป็นคีย์ดังนั้นจึงไม่จำเป็นต้องใช้คำสั่ง list(name_to_phone_list.keys()) เพื่อทำลิสต์ของคีย์เหมือนโค้ดก่อนหน้า
ดิกชันนารีที่แวลูเป็นดิกชันนารี#
ในการเก็บข้อมูลทำสมุดโทรศัพท์บางทีเราอาจอยากได้ข้อมูลช่องทางติดต่ออื่น ๆ นอกจากเบอร์โทร การใช้ดิกชันนารีที่มีแวลูเป็น ดิกชันนารีคู่ฟีลด์แวลู โดยที่แวลูแต่ละตัวจะมีฟีลด์ที่เหมือนกันทั้งหมด ทำให้เราสามารถเพิ่มช่องทางติดต่ออื่น ๆ ที่เราต้องการได้โดยง่าย เช่น ในตัวอย่างมีฟีลด์ที่เป็น 'phone' และ 'line'
name_to_info = {
('Mark', 'Wahlberg') : {'phone': ['111-222-3333', '444-555-6666'] , 'line': 'itsmemark'},
('Jane', 'Doe'): {'phone': ['222-3333-44444'] , 'line': 'janehomegirl'}
('Jane', 'Eyre'): {'phone': ['333-444-5555', '777-555-1111'], 'line': 'eyesonme'}
}
คำถามชวนคิด
จากโปรแกรมข้างต้น คำสั่งต่อไปนี้คืนค่าเป็น type อะไร
name_to_info[('Jane', 'Doe')]name_to_info[('Mark', 'Wahlberg')]['phone']name_to_info[('Mark', 'Wahlberg')]['phone'][0]name_to_info[('Jane', 'Eyre')]['address']
เฉลย
คำสั่ง |
คืนค่า |
ประเภทข้อมูล |
คำอธิบาย |
|---|---|---|---|
|
|
ดิกชันนารีคู่ฟีลด์แวลู |
|
|
|
ลิสต์ของสตริง |
|
|
|
สตริง |
|
|
|
- |
|
ตัวอย่าง: การนับไบแกรม#
ไบแกรม (bigram) คือ คำสองคำที่อยู่ติดกันในข้อความ เราสามารถเก็บไบแกรมและจำนวนครั้งที่เจอ ในโครงสร้างข้อมูลดังนี้
bigram = { ('a', 'dog') : 1235,
('a', 'very') : 2356,
('in', 'the'): 6222,
('in', 'a'): 8533,
('in', 'here'): 233,
('in', 'my'): 551
}
ข้อมูลข้างต้นถูกเก็บในดิกชันนารีที่มีลักษณะดังนี้
คีย์เป็นทูเปิลของสตริงสองตำแหน่ง ซึ่งแสดงถึงไบแกรม
แวลูเป็นตัวเลข ซึ่งแสดงถึงจำนวนครั้งที่พบไบแกรมนั้น
การจัดเก็บข้อมูลในโครงสร้างนี้จะเหมาะกับกรณีที่เรารู้ไบแกรมที่เราต้องการค้นหาจำนวนครั้งแล้ว เพราะคีย์ที่ใช้ในการเข้าถึงแวลูเป็นทูเปิลของสตริงสองตัวที่เป็นไบแกรมหากเรายังไม่รู้ไบแกรมที่ชัดเจน แต่ต้องการรู้ว่าคำ ๆ นี้มีคำอะไรต่อตามมาบ้าง โครงสร้างข้อมูลต่อไปจะเหมาะสมกว่า
bigram = { 'a': {'dog': 1235,
'very' : 2356},
'in': {'the' : 6222,
'a' : 8533,
'here': 233,
'my' : 551}
}
ข้อมูลข้างต้นเป็นดิกชันนารีที่มีลักษณะดังนี้
คีย์เป็นสตริง ซึ่งแสดงถึงคำแรกในไบแกรม
แวลูเป็นดิกชันนารีที่รวมคำทั้งหมดที่สามารถต่อท้ายคำแรกในไบแกรมได้ โดยมีลักษณะดังนี้
คีย์เป็นสตริง ซึ่งแสดงถึงคำที่สองในไบแกรม
แวลูเป็นตัวเลข ซึ่งแสดงถึงจำนวนครั้งที่พบไบแกรมนั้น
โครงสร้างข้อมูลลักษณะนี้นอกจากจะทำให้เรารู้จำนวนครั้งที่พบไบแกรมแล้ว ยังทำให้เรารู้ได้ว่าคำ ๆ หนึ่งสามารถต่อท้ายด้วยคำว่าอะไรได้บ้าง เช่น หากอยากรู้ว่าคำว่า ‘in’ มีคำอะไรต่อท้ายได้บ้าง สามารถเขียนโปรแกรมได้ ดังนี้
bigram['in']
จะได้ผลลัพธ์ออกมาเป็น
{'the' : 6222,
'a' : 8533,
'here': 233,
'my' : 551}
ซึ่งแสดงให้เห็นว่าคำ ‘in’ ต่อท้ายด้วยคำ ‘the’ 6222 ครั้ง ต่อท้ายด้วยคำว่า ‘a’ 8533 ครั้ง ต่อท้ายด้วยคำว่า ‘here’ 233 ครั้ง และคำว่า ‘my’ 551 ครั้ง
สรุป#
ลิสต์ของลิสต์ ลิสต์ของทูเปิล ลิสต์ของดิกชันนารีเป็นโครงสร้างข้อมูลที่ชั้นนอกสุดคือลิสต์ที่มีหน้าที่เก็บข้อมูลที่มีลักษณะคล้ายกัน เช่น ลิสต์ที่เก็บข้อมูลเดี่ยวประเภทเดียวกัน ทูเปิลที่มีจำนวนสมาชิกเท่ากัน และข้อมูลเดี่ยวประเภทเดียวกัน ดิกชันนารีที่มีคีย์เหมือนกัน เป็นการเพิ่มกรณีการใช้งานของลิสต์จากที่เราเคยใช้เก็บข้อมูลเดี่ยว เพิ่มมาเป็นการเก็บข้อมูลแบบคอลเลกชัน
นอกจากนั้นในบางกรณีเราจำเป็นต้องใช้โครงสร้างข้อมูลของดิกชันนารีที่ซับซ้อน ซึ่งที่มีประเภทของข้อมูลหลากหลายในส่วนของคีย์หรือแวลูไม่ว่าจะเป็นดิกชันนารีที่มีคีย์เป็นทูเปิล ดิกชันนารีที่มีแวลูเป็นลิสต์ ดิกชันนารีที่มีแวลูเป็นดิกชันนารี หรือดิกชันนารีที่มีแวลูเป็น ดิกชันนารีคู่ฟีลด์แวลู ซึ่งเป็นประโยชน์ในการนำไปใช้งานในหลายด้าน เราจะเห็นได้ว่าการค้นหาข้อมูลในดิกชันนารีจะสามารถเขียนโปรแกรมได้กระชับและรวดเร็วกว่าการค้นหาข้อมูลในลิสต์ และดิกชันนารีจะยังทำให้เราสามารถเก็บข้อมูลได้หลากหลายมากขึ้นขณะที่ยังสามารถค้นหาได้โดยง่ายต่างจากการใช้ทูเปิลยาว ๆ ในการเก็บข้อมูล